API 개발팀 Spring Batch 도입기
안녕하세요. 코드에프 API 를 개발 및 운영하고 있는 API 개발팀입니다.
최근에 팀에서 진행한 스프링 배치 프로젝트를 소개해보려고 합니다.
배치란? 스프링 배치란? 🤔
배치 는 일정 시간마다 또는 특정 조건에 따라 대규모 데이터를 일괄 처리하는 방식을 의미합니다.
스프링 배치(Spring Batch)는 이러한 배치 작업을 보다 쉽게 구현하고 관리할 수 있도록 돕는 프레임워크입니다. 스프링 배치는 스프링 생태계의 일환으로, 스프링의 강력한 기능을 활용하여 배치 작업을 안정적이고 효율적으로 수행할 수 있도록 지원합니다. 이를 통해 개발자는 복잡한 배치 처리 로직을 간결하게 구현하고 모니터링 기능을 통해 배치 작업을 효과적으로 관리할 수 있습니다.
스프링 배치와 스프링 스케줄러 차이
많은 개발자들이 이 두 가지를 혼동하곤 하지만, 스프링 배치(Spring Batch)와 스프링 스케줄러(Spring Scheduler)는 서로 다른 목적과 기능을 가지고 있습니다.
스프링 배치
대량의 데이터를 효율적으로 처리하기 위해 설계된 프레임워크입니다. 복잡한 배치 작업을 구성하고 실행하기 위한 다양한 도구와 기능을 제공합니다.
스프링 배치는 다음과 같은 기능을 제공합니다.
- 배치 프로세스를 주기적으로 커밋: 막강한 커밋 전략을 제공합니다.
- 동시 다발적인 job 의 배치 처리, 대용량 병렬 처리
- 실패 후 수동 또는 스케줄링에 의한 재시작: 오류에 대한 대처 옵션을 제공합니다.
- 반복, 재시도, skip 처리 : 실패한 배치 작업을 중단된 지점부터 다시 시작하거나 skip 할 수 있습니다.
- 모니터링: 배치 작업의 진행 상태와 소요 시간 등의 정보를 제공합니다.
- 트랜잭션 관리: 트랜잭션 관리를 지원하여 데이터의 일관성을 유지한다.
스프링 배치는 주로 금융, 전자상거래, 건강관리 등 대량의 데이터 처리가 필요한 도메인에서 널리 사용됩니다.
스프링 스케줄러
스프링 스케줄러는 특정 시간에 작업을 실행하기 위해 설계된 도구입니다. 반복적인 작업을 자동화하고, 시간 기반의 작업을 쉽게 설정할 수 있습니다.
스프링 스케줄러는 다음과 같은 기능을 제공합니다.
- 시간 기반 작업 실행: 특정 시간 또는 주기적으로 작업을 실행할 수 있습니다.
- 다양한 스케줄링 방식: 크론 표현식(Cron Expression) 또는 Fixed Delay 를 통해 작업 스케줄을 설정할 수 있습니다.
- 비동기 처리: 스케줄된 작업을 비동기적으로 실행하여 애플리케이션의 성능을 유지할 수 있습니다.
- 유연한 구성: XML 설정 또는 애노테이션을 통해 쉽게 설정할 수 있습니다.
스프링 스케줄러는 주로 정기적인 백업, 이메일 알림, 데이터 동기화 등의 작업을 자동화하는 데 사용됩니다.
| 특징 | 스프링 배치 (Spring Batch) | 스프링 스케줄러 (Spring Scheduler) |
|---|---|---|
| 목적 | 대량 데이터 일괄 처리 | 시간 기반 작업 실행 |
| 주요 기능 | 트랜잭션 관리, 재시작 및 중단, 데이터 검증 및 오류 처리 | 크론 표현식, 고정된 지연, 비동기 처리 |
| 사용 사례 | 금융 데이터 처리, 대량 파일 처리, 시스템 통합 | 정기 백업, 이메일 알림, 데이터 동기화 |
| 구성 방식 | 주로 XML 설정 또는 Java Config | 애노테이션 또는 XML 설정 |
스프링 배치를 도입한 이유 🥸
저희 팀은 스케줄러 서버를 유지, 운영하고 있어요.
오픈 초창기에 개발했던 소스를 문제가 생길 때마다 일부 개선해왔던 상황인데, 최근 API 호출량이 많아지면서 스케줄러 프로젝트에서 일부 개선 만으로 해결이 어려운 문제들이 드러나기 시작했습니다.
첫번째 문제는 API 요청 분류 스케줄러의 정체 현상입니다. API 호출을 저장하는 테이블을 조회해 분류 후 각 요청 정보 테이블에 저장하는 스케줄러에서 정체 현상이 일어난 것인데요.
요청 정보 테이블을 기준으로 서비스 운영이 되고 있기 때문에 정체 현상이 길어질 경우 호출건에 대한 확인과 고객 문의에 빠른 대응이 어려워집니다.
두번째 문제는 스케줄러 프로젝트 내에 워낙 많은 스케줄러로 인한 모니터링의 불편함입니다. 물론 API 운영에 직접적인 영향을 주지 않는 스케줄러여서 팀에서 신경을 못쓴 것도 있었지만, 스케줄러 현황을 한눈에 파악하기 힘든 것이 가장 큰 원인이었습니다.
이에 대해 스트레스를 계속 받았던 저희 팀은 개선 방안을 논의하기 시작했고 대량 데이터에 대한 빠른 처리, 모니터링과 관리의 편의성 을 모두 가져갈 수 있는 스프링 배치를 도입하기로 했습니다.
스프링 배치는 저희 팀 모두에게 생소한 프레임워크 이기 때문에 공부가 필요했습니다.
공부를 병행하며 진행한 프로젝트인 만큼 난관을 겪으며 기억에 남는 일들이 많았는데요.
설계, 개발, 테스트 과정에서의 일화들을 공유해보겠습니다.
설계
전체적인 프로세스는 Chunk 지향 프로세스를 사용하기로 했습니다.
Chunk 지향 프로세스는 ItemReader, ItemProcessor, ItemWriter 인터페이스를 사용해서 chunk 단위로 데이터를 처리하는 것입니다.
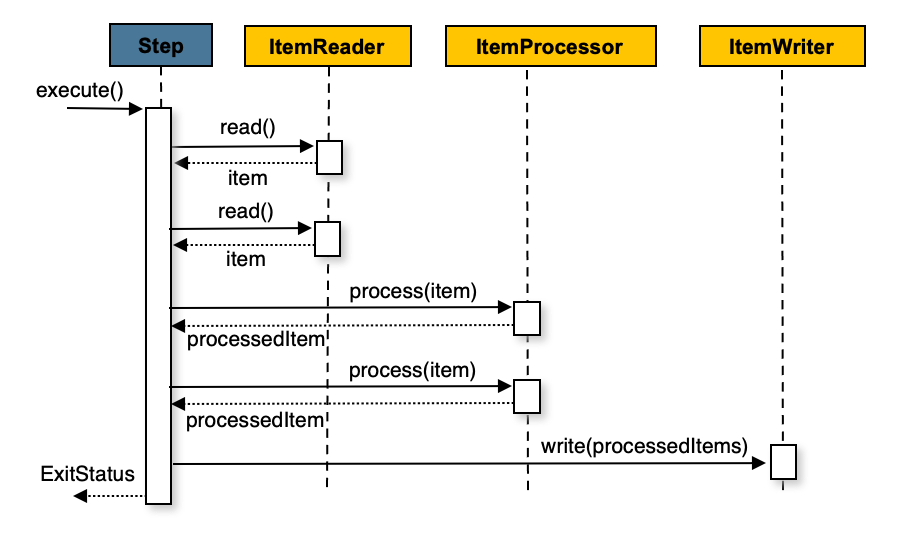
처음으로 시작한 개발건은 저희팀에 많은 스트레스를 주었던 ‘API 요청 분류 스케줄러’ 입니다. 단순히 read 하고 write 하는 것이라면 설계 고민도 없었겠지만 생각보다 단순하지 않은 프로세스여서 설계에 많은 고민이 있었어요.
분류가 목적인 기능이기 때문에 하나의 테이블을 read 후 조건에 따라 여러 테이블에 write 하는 프로세스 입니다. 가장 고민이 됐던 건 여러 Step 에서 동일한 데이터를 read 하니까 reader 가 중복되는 것이었어요.
같은 데이터를 여러번 DB 조회해온다는 것은 비효율적이기 때문에 한번만 DB 조회하고 데이터를 공유하며 쓰고 싶었어요. 하지만 이에 대한 트레이드오프(trade-off)로 기술 난의도가 올라가고 코드가 복잡해진다는 단점이 생기게 됩니다.
배치 프로젝트 경험이 없다보니 어떤 방법이 최적인지에 대한 확신이 부족했습니다.마침 팀에서 스프링 배치 강의를 함께 듣고 있어서 강사님 의견을 얻기 위해 질문을 올렸고, 감사하게도 답변을 주셔서 도움이 많이 되었습니다.
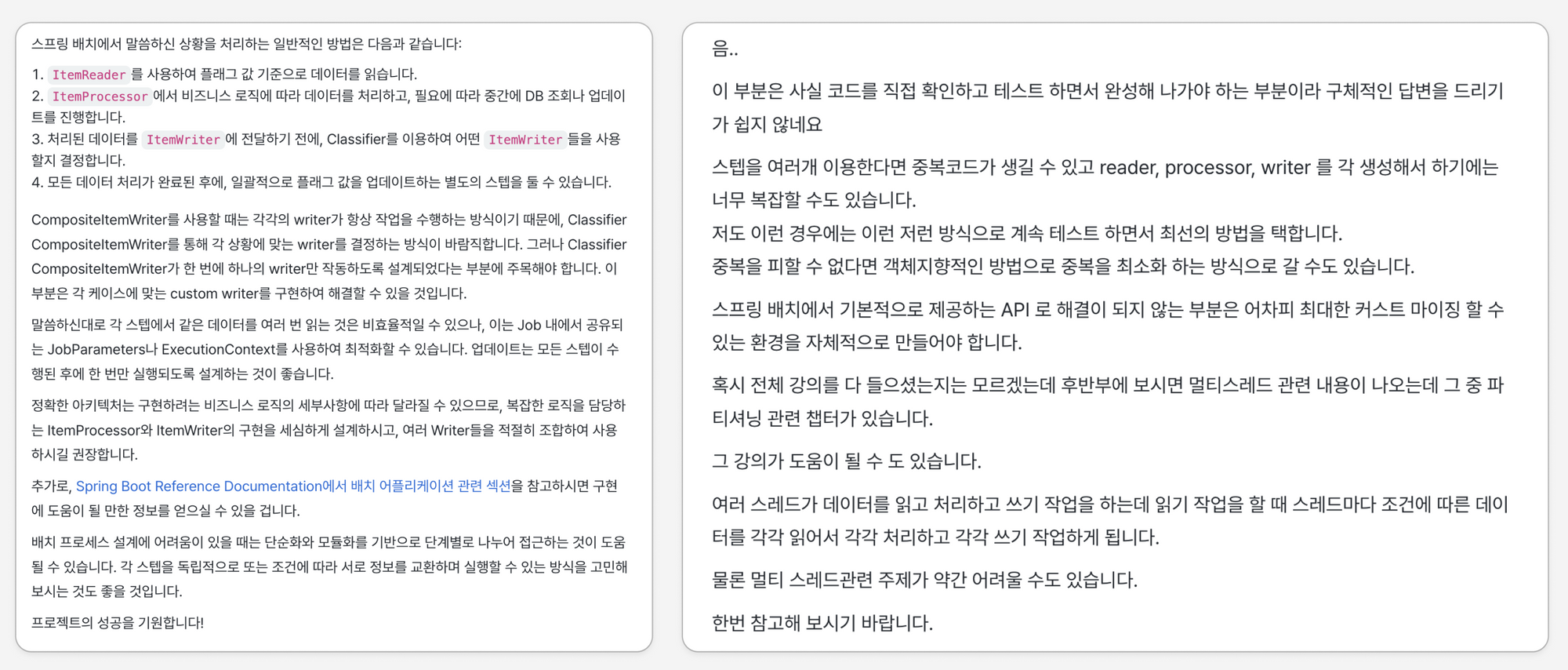
답변을 토대로 구글링도 하면서 이러한 결론을 내렸습니다.
중복을 줄이기 위해 job 의 여러 스텝에서 한번의 read 데이터를 공유하고 싶을 수 있다. 하지만 이는 배치에서 제공하는 기능이 없어서 기술적으로 까다로울 뿐더러, 각 write 당 한번씩의 read 가 있어서 read - write 가 되는 것이 스프링 배치 Chunk 프로세스에 더 적합하다. read 데이터가 중복이 되더라도 Step 은 깔끔하게 read - write 로 하자.
개발
저희는 chunk 지향 프로세스를 사용하기 때문에 ItemReader와 ItemWriter 인터페이스를 구현하는 구현체를 선택해야 했습니다. 다양한 구현체 중에 저희 팀은 JdbcPagingItemReader / JdbcBatchItemWriter 를 적용하였습니다.
[ItemReader 타입]
| CursorItemReader | PagingItemReader | |
|---|---|---|
| 조회 방식 | Cursor를 한 칸씩 옮기면서 데이터 조회 | 페이지 단위로 데이터를 한 번에 조회 |
| Connection | 하나의 DB Connection으로 Batch가 끝날 때까지 사용 | 페이지 단위로 DB Connection 연결 |
| 메모리 | 모든 데이터를 메모리에 저장 | 페이징 단위의 결과만 메모리에 저장 |
| Thread Safe | X | O |
위 특징들을 보면 커넥션 시간과 메모리 설정을 잘 할 수 있을 때는 cursor 방식이 성능상 유리하다고 볼 수 있습니다. 저희는 멀티 스레드를 적용할 계획이 있었고, DB Connection을 짧게 유지하는 걸 선호했기 때문에 paging 방식을 선택했습니다.
기존 프로젝트에서 mybatis를 사용하고 있어 PagingItemReader 중에서 mybatis 구현체도 고려했었어요. 사용하는 sql 구문이 복잡하지 않아 간단하게 구현 가능한 JdbcTemplate 인터페이스 구현체가 적합하다고 판단했고, 실제로 Jdbc, Jpa, Mybatis 세가지를 직접 적용해서 테스트해 본 후 JdbcPagingItemReader / JdbcBatchItemWriter 를 최종적으로 선택하게 되었습니다.
추가로 JdbcBatchItemWriter는 쿼리를 일괄 처리 하기 때문에 어플리케이션과 DB 간 왕복 횟수가 줄어들어 성능이 향상되는 특징이 있습니다.
테스트
테스트는 크게 두가지에 중점을 두고 진행했습니다.
첫번째는 대량 데이터 처리 테스트입니다. 대량 데이터가 쌓여있을 때 정체 없이 정상 처리가 되는지 확인이 필요했습니다. 대량 더미 데이터로 정체 없이 배치가 정상 처리되는지와 기존 스케줄러 대비 처리 속도를 테스트하였습니다.
두번째는 실시간 운영 중인 운영 환경과 동일한 환경에서의 테스트입니다. 운영 환경과 최대한 같은 테스트 환경을 갖추기 위해 테스트용 임시 스케줄러를 개발해서 운영 DB와 테스트 DB에 같은 시간에 같은 데이터가 들어오도록 환경을 설정하였습니다.
신규 오픈이 아닌 기존 기능을 교체하는 것이기 때문에 테스트 기간을 길게 잡고 약 2주 동안 데이터의 정합성, 정체 현상 발생 여부, 처리 속도를 전체적으로 테스트 했습니다.
🤸♂️ 개선된 점 🏋️♂️
속도
스프링 배치를 도입하면서 성능적으로 가장 기대했던 부분은 속도 입니다.
과거 스프링 스케줄러를 사용할 당시에는 정체 현상이 있을 때 반나절은 지나야 정체가 풀리곤 했었는데요.
배치를 도입한 후 어떻게 개선되었을까요?
Job 최대치가 4000개로 되어 있을 때 최대치를 수행한 경우만 가져와봤습니다.
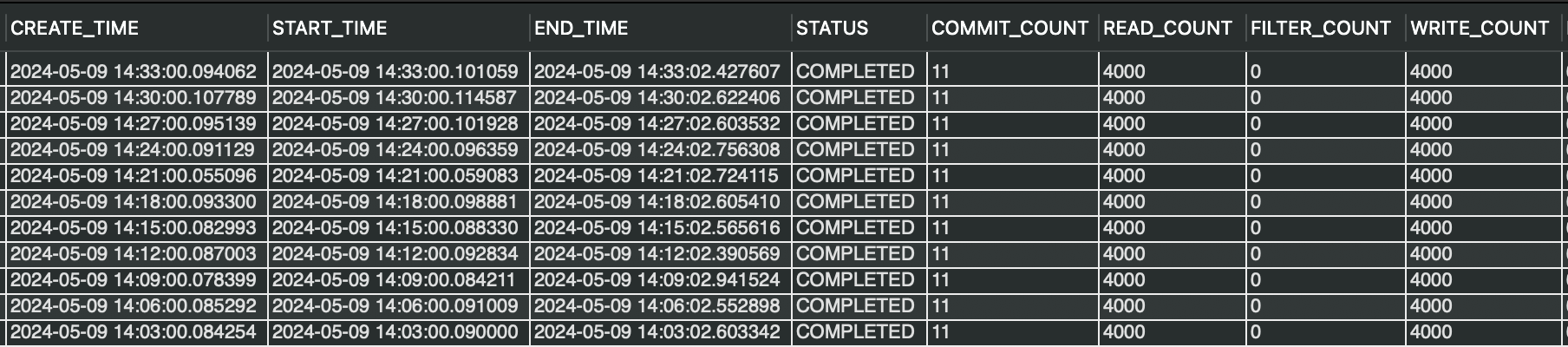
4000건을 처리하는데 약 2초가 걸립니다. 계속 쌓이는 요청 내역 처리를 빠르게 해야 하는 상황에서 4000건이 2초만에 빠지니까 정체 현상이 사라졌습니다.
모니터링
스프링 배치를 사용하면 모니터링에 이점이 있습니다.
스프링 배치에서 제공하는 기본 기능으로 배치 작업 동안 사용하는 모든 메타 데이터들을 기록하는 메타테이블이 있습니다.
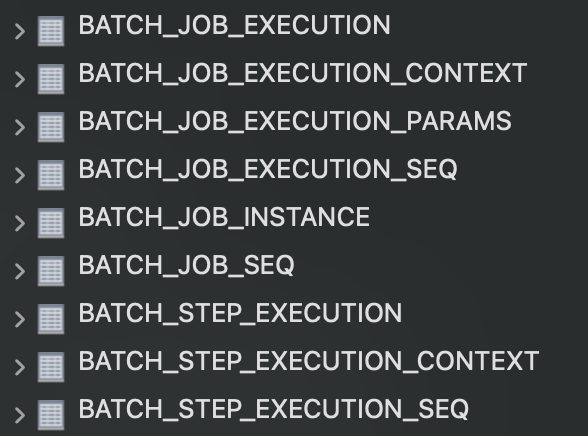
메타테이블을 확인하면 현재 진행 중인 배치와 성공 실패 여부, 수행 시간 등 많은 정보를 모니터링 가능합니다. 로그 파일을 열어보는 것이 아니고 테이블 조회로 바로 확인이 되니 모니터링이 수월해졌습니다. 이외에도 오류에 빠르게 대응할 수 있도록 리스너를 이용해 오류 발생시 팀 슬랙 채널에 알림이 오도록 개발했습니다.
추가 개선이 필요한 부분
모니터링 어드민
스프링 배치에 쿼츠(Quartz)를 적용해서 사용 중인데요. 쿼츠에도 메타테이블이 있습니다. 스프링 배치와 쿼츠 메타테이블을 활용해 화면상에서 모니터링 할 수 있는 어드민 페이지를 구상 중입니다. 단순히 현황을 확인하는 것 뿐만 아니라 배치를 멈추고 실행시키는 것 까지 관리할 수 있는 통합 페이지를 개발하는 것이 최종 목표입니다.
배치와 스케줄러 구분
사실 배치 작업은 실시간으로 처리되어야 하는 기능에 딱 들어맞게 적합한 것은 아닙니다. 배치는 정해진 시간에 대량 데이터를 일괄 처리하는 작업을 의미합니다.
이번에 스케줄러에서 배치로 이관한 ‘API 요청 분류 스케줄러’ 는 실시간 처리가 필요한 기능이기 때문에 개발할 때 일반 배치 프로세스에서 발생하지 않을 법한 예외 케이스로 인해 어려움을 겪기도 했습니다.
일괄 처리 속도에 중점을 두고 배치로 이관한 것이어서 배치가 적합하다고 생각하고 성능 향상에 만족하고 있지만, 앞으로의 다른 스케줄러 이관부터는 명확한 기준을 두고 단순 스케줄링과 배치를 분리하려고 합니다.
⛳️ 마무리
지금까지 API 개발팀에서 진행한 스프링 배치 프로젝트 과정에서 있었던 일들을 소개해 보았습니다.
개발팀에 있어서 경험이 없는 기술로 새로운 프로젝트를 한다는건 언제나 긴장과 설렘을 주는 일입니다.
이상으로 개발 및 운영으로 바쁘지만, 개발팀답게 성장하고 있는 API 개발팀의 이야기였습니다 😎
출처
https://docs.spring.io/spring-batch/reference/step/chunk-oriented-processing.html
인프런 - 스프링 배치 강의 https://www.inflearn.com/course/스프링-배치


