
비개발자가 쉽게 설명하는 웹 크롤링(Crawling)과 웹 스크래핑(Scraping)의 차이점
데이터가 범람하는 시대, 우리는 원하는 정보를 얻기 위해 다양한 플랫폼을 이용하고 있습니다. 검색 포털부터, 구인구직 플랫폼, 숙박업소 정보 플랫폼 등 카테고리 별로 떠오르는 플랫폼만 해도 수십 가지일 정도이죠. 수많은 플랫폼 사이에서 고객들은 ‘양질의 데이터를 얼마나 많이 보유하고, 알맞게 보여주는지'에 따라 플랫폼을 선택합니다.
그렇다면 플랫폼들은 어떻게 인터넷의 수많은 데이터 속에서 고객이 원하는 정보만을 골라 보여줄 수 있는 걸까요? 이는 바로 ‘웹 크롤링(Web Crawling)’과 ‘웹 스크래핑(Scrapint)’ 기술을 활용하여 구현됩니다.
웹 크롤링(Web Crawling)이란?
웹 크롤링이란 웹상의 정보들을 탐색하고 수집하는 작업을 의미합니다. 인터넷에 존재하는 방대한 양의 정보를 사람이 일일히 파악하는 것은 불가능한 일입니다. 때문에 규칙에 따라 자동으로 웹 문서를 탐색하는 컴퓨터 프로그램, 웹 크롤러(Crawler)를 만들었습니다.
크롤러는 인터넷을 돌아다니며 여러 웹 사이트에 접속합니다. 그리고 페이지의 내용과 링크의 복사본을 생성하여 다운로드하고 요약본을 만듭니다. 그리고 검색 시 유용한 정보만을 노출하도록 검색 색인을 붙이죠. 이는 도서관에서 책을 찾기 위해 도서의 주제, 제목 등에 따라 분류 기준을 구성하는 것과 비슷한 작업입니다.
일련의 과정이 다소 어렵게 들리지만, 검색 포털을 떠올리면 쉽게 이해할 수 있습니다. 우리는 필요한 정보가 있을 때, 구글이나 네이버 등을 이용합니다. 검색창에 키워드를 입력하면 해당 포털의 URL을 지닌 페이지뿐만 아니라 외부 사이트 링크도 본문의 요약본과 함께 노출되는 것을 확인할 수 있습니다. 이러한 웹 페이지 목록 화면은 검색 엔진이 웹 크롤러가 수집한 데이터에 검색 알고리즘을 적용하여 정보를 추출해낸 결과입니다.

웹 스크래핑(Web Scraping)이란?
웹 스크래핑은 특정 웹 사이트나 페이지에서 필요한 데이터를 자동으로 추출해 내는 것을 의미합니다. 웹 스크래핑은 다음과 같이 작동합니다. 원하는 정보를 추출하기 위해 ‘스크래퍼 봇’이 특정 웹 사이트에 콘텐츠를 다운로드하기 위한 HTTP GET 요청을 보냅니다. 사이트가 이에 응답하면 스크래퍼는 HTML 문서를 분석하여 특정 패턴을 지닌 데이터를 뽑아냅니다. 그리고 추출된 데이터를 원하는 대로 사용할 수 있도록 데이터베이스에 저장합니다.
웹 스크래핑은 자동으로 수집된 특정 정보가 필요한 분야에서 다양하게 활용되고 있습니다. 금융 및 주식 시장의 경우, 스크래핑 기술을 활용하여 뉴스 정보를 모으기도 하고, 애널리스트들이 투자 자문을 위해 활용할 수 있는 기업 재무제표 정보를 자동으로 수집하기도 합니다. 전자상거래 시장의 경우 경쟁력 확보를 위해 경쟁사 상품의 정보를 수집하고 가격 변동 이슈를 빠르게 파악하기 위해 스크래핑 기술을 활용하기도 하죠.

웹 크롤링과 웹 스크래핑의 장점
심층 분석과 실시간 정보 제공에 유용한 “웹 크롤링”
웹 크롤링은 웹상을 돌아다니며 방대한 양의 정보를 수집하기 때문에, 특정 키워드에 대한 심층 분석이 필요할 때 유용합니다. 또한 크롤러는 실시간 정보 수집을 위해 계속해서 작동하므로 자주 변화하는 데이터를 파악하기가 좋습니다.
정확한 정보를 요구할 때 쓰이는 “웹 스크래핑”
웹 스크래핑은 특정 사이트나 페이지에 대한 정보를 찾는데 집중하므로 데이터 포인트를 정확히 잡고 확실한 정보만을 수집할 수 있다는 점에서 유용합니다. 장기적으로 서비스 대역폭이나 비용을 절약할 수 있다는 장점이 있습니다.
웹 크롤링과 웹 스크래핑의 차이점
크롤링과 스크래핑은 ‘원하는 데이터를 모을 수 있다’는 점이 비슷하여 의미가 자주 혼용되곤 합니다. 또한 기술적으로 함께 사용되는 경우가 많아 더욱 헷갈립니다. 하지만 웹 크롤링은 웹 페이지의 링크를 타고 계속해서 탐색을 이어나가지만, 웹 스크래핑은 데이터 추출을 원하는 대상이 명확하여 특정 웹 사이트만을 추적한다는 차이점이 있습니다.
또한 웹 크롤링은 페이지를 모아 색인화(분류)하고 검색 결과에 내가 찾는 키워드와 연관된 링크들만 모아 볼 수 있도록 작동합니다. 하지만 웹 스크래핑은 상품의 가격, 주식 정보, 뉴스 등 원하는 데이터가 명확하며, 흩어져있는 해당 데이터를 자동으로 추출하여 전달합니다. 이 외에 차이점은 아래 표와 같습니다.
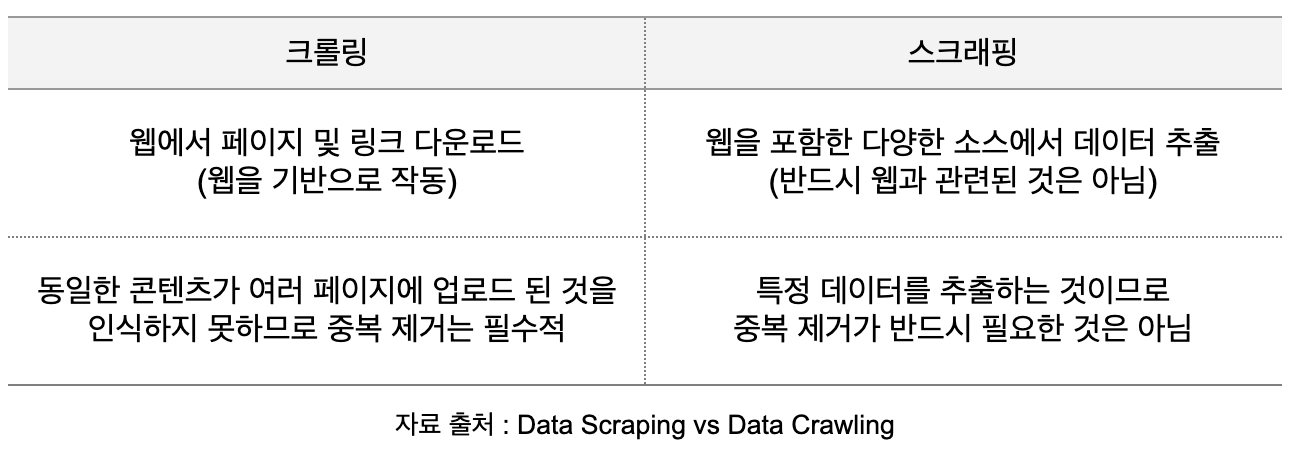
비슷한듯 다른 웹 크롤링과 웹 스크래핑. 기획과 개발에 있어서 어느 한 가지만을 선택하여 사용할 수는 없습니다. 웹 크롤링의 경우 모든 데이터를 모으기 때문에 정보의 확장성이 넓다는 장점이 있고, 서버의 자리를 많이 차지하여 리소스가 많이 들어간다는 단점이 있습니다. 웹 스크래핑은 반대로, 적은 리소스를 들여 정확한 정보를 가져올 수 있지만, 그만큼 데이터의 한계가 있죠.
따라서 서비스 이용자가 어떤 것을 원하는지에 따라, 두 가지를 적절히 선택하여 적용해야 합니다. 또한 데이터를 끌어오는 작업이기 때문에 저작권 문제 등 법적 분쟁 요소도 면밀히 따져보아야 하죠. 여러분은 오늘 코드에프 컨텐츠가 전달한 내용을 바탕으로 여러분의 서비스에 가장 알맞은 방법을 선택하시기 바랍니다 : )
[자료 출처]
- What Is The Difference Between Web Crawling And Web Scraping?
- What is data scraping? / CLOUDFLARE
- What is a web crawler? | How web spiders work / CLOUDFLARE
코드에프는 데이터를 활용한 핀테크 서비스를 지원하며 서비스 제공 기업이 온전히 서비스에만 집중할 수 있도록 돕습니다. 코드에프는 복잡한 절차를 간결하게 바꾸고 수고로움을 줄이고자 노력합니다. 또한 국내 시장에만 머무르지 않고 전 세계의 데이터를 중계해 주는 것을 목표로 합니다. 코드에프가 궁금하시다면 아래 배너를 눌러 코드에프의 API 서비스를 살펴보세요.

본 페이지 내의 모든 콘텐츠는 저작권법에 의해 보호받는 저작물로서, 모든 사용 권리는 ㈜코드에프에게 있습니다. 별도의 저작권 표시 없이 무단으로 사용하는 것을 금지하며, 자세한 저작권 정책은 해당 링크를 참고하시기 바랍니다.
Copyright 2022.㈜코드에프 All rights reserved.
![[아마존 셀러를 위한 솔루션 비교] 정글스카우트 vs 헬리움10, 한국 셀러에게 맞는 대안은?](/content/images/size/w720/2024/11/-----------2024-11-19-09.06.07.png)